一个验证码识别实验,欢迎star。https://github.com/xiaodouhua/captcha_recognition
实验用到的库主要是sklearn,建议下载anaconda即可
实验主要工作有以下几点:
- 批量下载验证码
- 验证码的处理,包括:去噪音,灰度化,二值化,切割
- 用svm+pca去训练数据
各个文件介绍:
- googleocr.py: 一行代码,主要用了google的pytesseract开源识别库,在此数据集上不能识别,应为数据是空心的。如果是实心的话,效果猜测不错(前一个项目就是直接用的,基本100%)
- scrapy.py: 爬取数据集
- slice_pic.py: 图片处理,切割等
- ml.py :利用sklearn库进行数据特征提取,pca降维,svm分类,保存了模型
- predict.py: 利用保存的预测
实验数据如下 :
共爬取了1000张,最后由于人工去标注的量太大,所以只用了分割后的910张去训练和测试准确率
训练数据为910*0.85,剩下的去测试,最后经过pca调参之后选取了降维到50个特征,切割后的单个图片的验证码识别率为85%~86%,所以验证码的识别率大概为0.85^4≈50%,效果一般,但是应该可以用了。
总结:
- 切割的非常好,因为数据集的原因,观察观察再观察,发现数据切割只要固定切割就行了,不需要发现空白竖线什么的(反而不好发现),而且恰好是均等分割,后面特征处理非常好处理。

- 训练结果在单个字符上也是不错的,在经过pca各种参数维度降维之后,选取了50。
不足之处:
- 噪音线条和数字字母的颜色太相近,很难去去噪,只去除了黑点和颜色比较深的部分,去除之后如下:

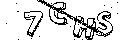
- 识别只用了机器学习的算法,看网上的资料说神经网络应该效果不错的。还有水滴算法等
- 数据集还是太少,人工需要把每个切割后的图片放到对应文件里面,很费时。如果数据量大的话,算法的准确率应该会再上一台阶。
